Best Practices: Crawling Microsoft® SharePoint
This guide will help with understanding the best practices for crawling Microsoft® SharePoint with Shinydocs Cognitive Toolkit.
Crawl the root
The ideal crawl is done at the root of Microsoft® SharePoint (ex. https://acme.sharepoint.com/sites). This will capture all sites, but remember to use the Cognitive Toolkit argument --crawl-subsites while crawling. Specific sites can be filtered later in the Visualizer and queried against with Cognitive Toolkit if needed.
Use a multi-index strategy
Microsoft® SharePoint is typically split into many sites and subsites, allowing organizations to make large and small repositories for their work. When crawling Microsoft® SharePoint, it’s important to preplan how the indices will reflect that data. It’s best to have an index per site when possible and this is the default behaviour of Cognitive Toolkit when using --crawl-subsites.
The value entered for -i/--index-name will be the root name for each index.
For example:
--index-name acme_spo
would result in indices that look like
acme_spo_<site_name>
acme_spo_accounting
acme_spo_projectB
acme_spo_projectA
The Visualizer and Cognitive Toolkit will be able to aggregate these indices under acme_spo*.
Only use additional arguments when needed
There are multiple arguments for different use cases in Cognitive Toolkit (ex. --remove-standard-filter, --hidden, --catalog), however, they should only be used if they are needed. These additional arguments usually capture special data that is only useful in some outcomes, it's best not to use all available arguments and only use arguments that align with the desired outcome.
Field data type conflicts
When crawling Microsoft® SharePoint, new fields in the index are created for each custom column applied to a file prefixed by cc-. The index automatically assigns an internal type to that field (boolean, number, date, text, etc.) based on the first entry, and it cannot be changed once it is set.
For example, in Microsoft® SharePoint there are files that have a column called “Username”. Some of the values are traditional names and some usernames are just numbers.
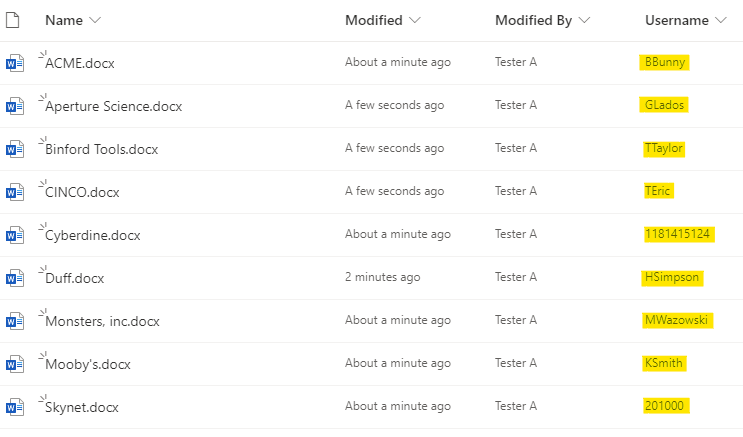
If the first file crawled contains a Username value of “BBunny”, the index will treat the Username column as a text field and text fields can contain letters, numbers and symbols. When it comes time to ingest a file with a numerical-only value, it will ingest fine as the field has been marked as text.
If the first file crawled contains a Username value of “1181415124”, the index will automatically treat the Username field as a number field. When it comes time to ingest a file with letters, the index will reject the document stating there is a field type conflict.
This issue can occur often using the single index option (--use-single-index), but is less likely to happen if using a multi-index strategy (though still possible). This scenario will require assistance and custom index mapping.
Crawling SharePoint Online with a large number of subsites
This applies to Microsoft® SharePoint Online only
When crawling Microsoft® SharePoint Online, there may be so many subsites that it becomes a problem for Cognitive Toolkit to gather them each time a crawl is initiated due to limitations in the Microsoft® SharePoint API. In this case, it’s best to use CrawlSharePointOnlineSites in Cognitive Toolkit. This will create an index that can be used with CrawlSharePointOnline and contains a list of SharePoint sites to crawl.
When automating these crawls, always have CrawlSharePointOnlineSites run before CrawlSharepointOnline
Perform a crawl using
CrawlSharePointOnlineSitesThe name of the index for
--index-name should beshinydocs-sites-sposince this is a system index
CrawlSharePointOnlinewith--crawl-from-index shinydocs-sites-spo.
Limitations
1000 subsites per Analytics node
It is best practice to assume 975 per node realistically, as there are system indices that also must be taken into account
This limit is imposed to prevent the Analytics Engine from degraded performance and memory limit issues
At most 1000 custom SharePoint columns
Per site if using an index per site
In total if using
--use-single-index