System Monitoring Considerations for Shinydocs Indexer Servers
When using the Shinydocs Cognitive Suite in a production environment, it is recommended to have monitoring in place to identify potential bottlenecks or problems quickly. This guide will focus on the basics that should be monitored, their threshold, and some options on how to address problems that arise.
This monitoring guide should only be used on servers running the Shinydocs Indexer exclusively and should not be used if you are using the Cognitive Toolkit on the same machine as the Shinydocs Indexer
There may be specific use-cases that this guide does not apply to
CPU Utilization Monitoring
The CPU utilization of any cluster node/server will vary based on many factors such as CPU brand, model, configuration.
Health Check
A healthy-performing CPU within the Shinydocs cluster may still have a sustained load over days/weeks/months, but will also have peaks and valleys. There is no specific way a CPU should be utilized, and CPU architecture does play a role in how it is used. It is normal to have peaks and valleys in usage.
Danger Zone
If CPU utilization is greater than 90% for 12 hours on one node/server
Restart the server to rule out a runaway thread
There may be a shard imbalance where too many hot shards are on one server. Elasticsearch balances this on its own. A restart should fix this issue
There may be other processes active on that node (backups, applications, scripts, etc). These processes should be moved to another server to maintain cluster performance
If your configured JVM memory on this node (configured in jvm.options) is lower than other nodes in the cluster and is constantly >90% JVM usage, you may need to expand your memory. Java’s garbage collection is activated upon reaching 75% JVM usage. Having your nodes JVM >90% usage means the CPU has to work a lot harder doing the garbage collections. Memory or node expansion may be the solution.
If CPU utilization is greater than 90% for 12 hours on more than one node/server
If all data holding nodes have a sustained CPU load of 90% or higher, this is a clear indicator that the cluster requires more CPU resources
Note: if your JVM heap for each node is consistently above 90%, the high CPU could be from frequent and/or long-running Java garbage collection. This may be an indicator you need to give the nodes more memory (30G Max Heap on 64 GB Windows Machine) or add additional nodes to balance JVM memory pressureThere may be backups or AV scans on these nodes, causing the cluster to slow down due to a lack of CPU resources
Restarting the cluster may offer temporary relief, however, you should expect the utilization to return to >90% after some time
Caution Zone
If CPU utilization is greater than 85% for 12 hours on one node/server
May indicate there is another process running
May indicate a shard imbalance where too many hot shards are on one server. Elasticsearch balances this on its own. A restart should fix this issue
If your configured JVM memory on this node (configured in jvm.options) is lower than other nodes in the cluster and is constantly >90% JVM usage, you may need to expand your memory. Java’s garbage collection is activated upon reaching 75% JVM usage. Having your nodes JVM >90% usage means the CPU has to work a lot harder doing the garbage collections. Memory or node expansion may be the solution.
If CPU utilization is greater than 85% for 12 hours on more than one node/server
If all data holding nodes have a sustained CPU load of 85% or higher, this is a clear indicator that the cluster will require more CPU resources in the near future. Adding more CPU cores or additional nodes is the recommendation to alleviate this issue.
Note: if your JVM heap for each node is consistently above 90%, the high CPU could be from frequent and/or long-running Java garbage collection. This may be an indicator you need to give the nodes more memory (30G Max Heap on 64 GB Windows Machine) or add additional nodes to balance JVM memory pressure
Memory Utilization (RAM) Monitoring
Danger Zone
If Memory (RAM) utilization is greater than 90% for 12 hours on one node/server
Likely not an issue, that particular node may be doing some heavy lifting or automatic shard operations
If the node maintains >90% RAM utilization for 24 hours, there may be another process running on the node that shouldn’t be.
If there is no indication of a problem on that node, but memory is still >90%, restart the node.
If Memory (RAM) utilization is greater than 90% for 12 hours on more than one node/server
This would indicate that the cluster needs more memory.
The maximum memory assigned to one node should not exceed 64 GB
On a 64 GB system, the ideal JVM setting is 30 GB
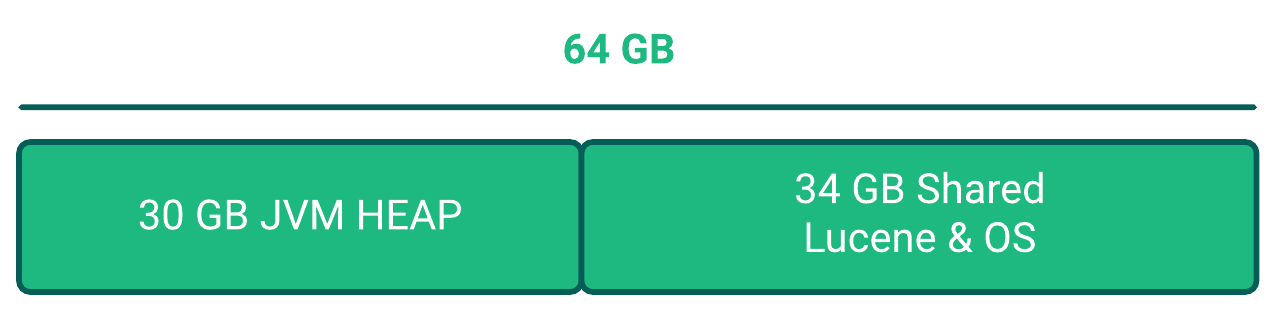
Your JVM settings on Windows should not exceed 30 GB
If all of your nodes are at 64 GB:30 GB, you should add another similar node to the cluster
Caution Zone
If Memory (RAM) utilization is greater than 75% for 12 hours on one node/server
Likely not an issue, that particular node may be doing some heavy lifting or automatic shard operations
If the node maintains >75% RAM utilization for 24 hours, there may be another process running on the node that shouldn’t be.
If there is no indication of a problem on that node, but memory is still >75%, restart the node
If Memory (RAM) utilization is greater than 75% for 12 hours on more than one node/server
Considered the edge of healthy memory usage.
No action is needed, but this does indicate memory pressure is building, you will likely need to add more RAM soon (if your nodes are below 64:30), or add additional nodes to prevent future problems
Disk (Storage) Monitoring
Danger Zone
If disk storage is greater than 95% used on any node
This node will go into read-only mode, bringing down the performance of the cluster
May result in crawls not being able to ingest data into the node
Disk space should be increased immediately
Ensure you don’t have any indices that are not needed anymore. If you do, delete them
You may not be able to delete the index if the cluster is in a read-only state.
Add additional storage, then delete the old/unused indicies
You may need to run a command to tell the cluster that the disk space is resolved and the node can be used again. https://enterprisefile.atlassian.net/wiki/spaces/SHINY/pages/607256577
Caution Zone
If disk storage is greater than 85% used on any node
This node will need additional disk space/storage soon
Should be corrected before reaching =>90% used
Ensure you don’t have any indices that are not needed anymore. If you do, delete them