FAQ: Duplicates
Duplicate files are files that are identical copies of each other. Depending on your environment, you may have files with just a few copies on your network, or perhaps some that have hundreds or even millions of copies. These duplicate files can:
occupy costly and valuable disk space
distort search results
skew data analytics reports
create legal liability if legal holds and retention rules have not been applied
How do we find duplicates?
Shinydocs Cognitive Suite provides the ability to locate duplicates, even amidst unmanaged data. We do this by generating a hash for each file.
There are various algorithms available for generating hash. We commonly recommend either md5 (Message Digest Algorithm 5) or sha1 (Secure Hash Algorithm 1), both of which are integrated with our tools.
Applying one of these hashing algorithms, we generate hash values for each file. Then, we use the hash within our tools to determine if files are identical copies of each other. It is faster to find an item using the shorter hashed key than to use the original value.
What is hash?
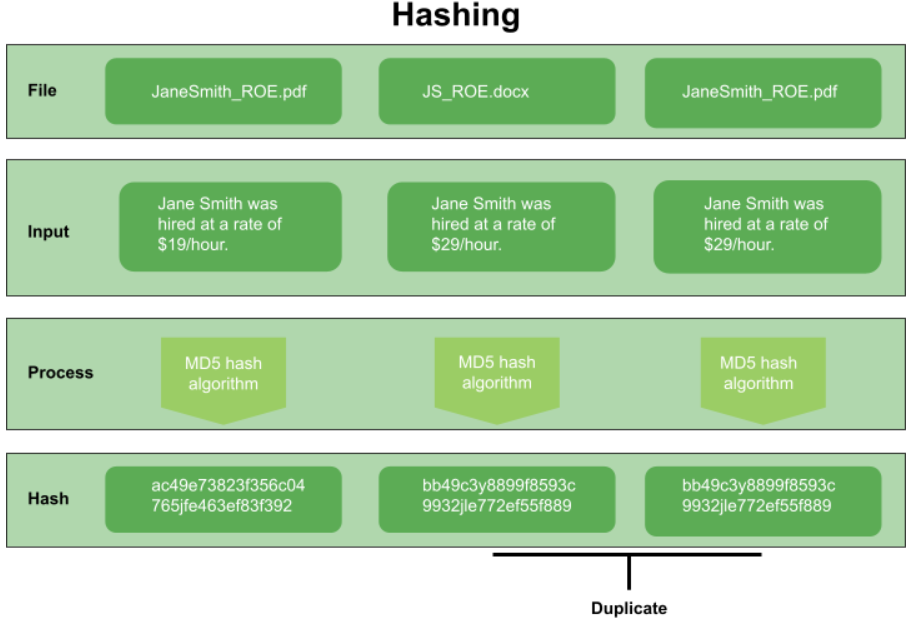
Hashing is the transformation of an object as input and produces a representative number or a string as output. These input objects can vary from numbers and strings (ie. text) to large byte streams (ie. files or network data). The output is usually known as the hash of the input.
In other words, the process of hashing generates a code for each file crawled. Here is an example of a hash code: bb49c3y8899f8593c9932jle772ef55f889
What if documents have the same content, but different file names?
The hash of a file is based on the content of the file only. The name of the file and the file type are irrelevant when comparing duplicate files.
For example, although the file names and extensions are different in the files listed below, the document itself has been determined to be a duplicate after comparing the files byte per byte. The result is matching hash values.
File Name | Hash Value |
JaneSmith_ROE.pdf | bb49c3y8899f8593c9932jle772ef55f889 |
JS_ROE.docx | bb49c3y8899f8593c9932jle772ef55f889 |
What if documents have almost the same content?
Files can have the same hash only if their contents are exactly the same. If two or more files have the exact content, the hash value will be the same thus identifying it as a duplicate.
A single character variation within the content will generate a completely different hash value.
For example, the documents below had a single character change from $19 to $29. This discrepancy results in the generation of an entirely different hash code, indicating that the first document is NOT a duplicate, even though it shares the same file name as the third document.