Incident Management at Shinydocs
All Shinydocs customers deploy our solutions on-premises, in their own data centers, rather than hosted by us in the cloud. As a result, Shinydocs cannot automatically detect customer incidents remotely; we rely on the operator or administrative user at each customer to notify Shinydocs of any new issues or incidents as they occur.
Traditional tools for measuring a vendor's effectiveness when dealing with incident detection and incident management, such as service availability, uptime, recovery point objectives (RPOs), or recovery time objectives (RTOs) are not tracked against Shinydocs, as the customers themselves manage the performance and availability of their own environment.
Independently of these factors above, Shinydocs does provide strong guidance for customers looking to establish a robust incident management or IT service management model for our solutions. This guidance supports our customers' admin users and operators as they diagnose and troubleshoot issues in their labs and data centers.
Guidance on Incident Management
At Shinydocs, Incident Management refers to a set of processes and solutions that allow our customers to detect, investigate and respond to incidents as they occur in their on-premises labs or data centers. Having a strong Incident Management practice in place is critical for all Shinydocs customers. It ensures that IT teams can react and deal with issues as they occur and when used in combination with an effective problem management practice, reduce the likelihood of having incidents reoccur.
Five Stages of Incident Management
Shinydocs adheres to industry-accepted standards for defining each of the five stages of Incident Management. These stages can be applied to incidents of all types, up to and including security-related incidents:
Incident Identification
Incident Notification / Communication / Reporting to Shinydocs
Investigation and Troubleshooting
Resolution and Recovery
Incident Closure
Since all Shinydocs customers have our software deployed on-premises, Steps 1 and 2 (above) are the responsibility of our customer operators / admin users. Steps 3, 4 and 5 (above) are shared responsibilities between Shinydocs and our customers.
Severity Levels
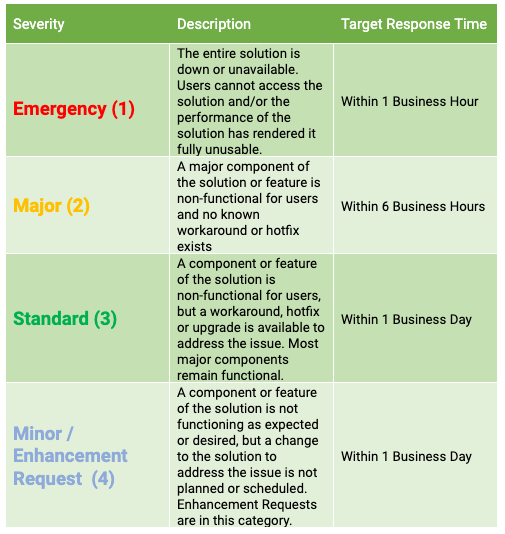
At Shinydocs, incidents/tickets are triaged and actioned based on Severity Levels, this applies to production environments and is not applicable during the pre-live project implementation phase. Severity level is determined by the criteria in the table below along with their targeted response times. Business Hours are currently defined as Monday - Friday 8:00am-5:00pm UTC-4 (Eastern Time) exclusive of observed holidays. During an observed holiday we maintain a reduced staff to respond to any Emergency tickets. Any non-Emergency severity tickets will be actioned the following business day.
Escalation Management
Incidents/Tickets at Shinydocs are constantly reviewed to ensure a timely response and resolution. We employ several reporting methods, dashboards, and regular ticket reviews to reduce the potential for escalations. In addition, customers can escalate tickets/incidents directly by the following process:
Step 1: Via the Ticket: Customers can flag a ticket for escalation via a direct ticket update. This is a required first step for an escalation. Upon resolution of escalated emergency and major severity tickets, a retrospective (retro), including future preventative measures will be created and shared with the customer if applicable.
Step 2: Via Shinydocs Management: If the incident/ticket has been escalated but a satisfactory solution has not been provided, the issue can be escalated to the Customer Support Manager. The Support Manager will develop an action plan for resolution and engage internal stakeholders as necessary, ensuring timely customer updates. Upon resolution of escalated emergency and major severity tickets, a retrospective (retro), including future preventative measures will be created and shared with the customer if applicable.
Step 3: Shinydocs Senior Leadership: If the ticket has been escalated via the ticket and through the Support Manager and no satisfactory resolution has occurred, the issue may be escalated to the VP of Customer Success.