Extracting full text from a file share
By using the Full Text Extraction tool, the full text of your document(s) will be searchable and can be used to help identify and narrow down your data and to create more comprehensive business visualizations.
Shinydocs Cognitive Suite enables you to extract the full text from specified file(s) within the index that was created during the initial metadata crawl. Before you begin, ensure that initial discovery has been completed and basic metadata has been extracted. If not, refer to: Initial Discovery - File Share
Step by step:
Create a query based on the file(s) from which you would like to extract full text. This query will be referenced when we run the full text extraction tool. This query should be saved as a .json file.
Example query:
{
"bool": {
"must_not": {
"exists": {
"field": "fullText"
}
},
"must": [
{
"terms": {
"extension": [
"xls",
"xlsx",
"xlsm",
"xlt",
"csv",
"ods",
"odp",
"odt",
"txt",
"doc",
"docx",
"docm",
"rtf",
"pot",
"potx",
"ppt",
"pps",
"ppsx",
"msg"
]
}
}
]
}
}The above script will extract full text from only files that have NOT previously had text extraction performed. The tool will only run against the list of extensions mentioned.
Open a command prompt as an Administrator
Navigate to the CognitiveToolkit root folder
Run the AddHashAndExtractedText tool by inputting the following command and replacing the required fields according to your environment:
CognitiveToolkit.exe AddHashAndExtractedText --action-keyword text --max-characters {max_characters} --query {path-to-file} -u {url-to-index} -i {name of index}We recommend including a --max-characters value to limit the numbers of characters deep into a document from which full text is being extracted. Extremely large documents can significantly affect progress if the maximum character value is not included.
Sample command with a maximum character value of 30,000 characters:
CognitiveToolkit.exe AddHashAndExtractedText
--action-keyword text
--max-characters 30000
-q "C:\match_all.json"
-u http://localhost:9200
-i testdata Validation
A refresh of the index must be done after running full text extraction. Refreshing the index will add the new fields and values to the selected index
Refreshing a Index
Within a Web Browser (A Chromium Browser is recommended), enter the address for where Shinydocs Analytics has been installed. This is typically <machine-name>:5601. If you are running the tool locally, use "localhost:5601".
Select Management > Index Patterns and the index you ran Full Text Extraction towards

Select Refresh on the far right

You should then see the number of fields increase

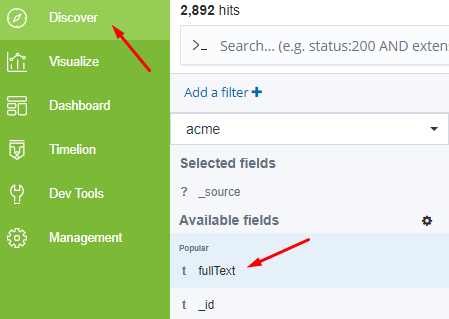
Navigate to the Discover Tab and you will see fullText now under the Available fields section
Did you know…
There are two ways to run tools in CLI:
Using the full command (as shown above).
Or using .bat files. Every installation of Shinydocs Cognitive Suite comes with a folder of .bat files. Use these as a starting point for customizing commands to your specific environment.Run this CLI command: COG-Query-AddFullText-less-1MB-less32K-chars.bat
Example .bat file (COG-Query-AddFullText-less-1MB-less32K-chars.bat) and .json file (query-math-path-no-fullText-less-1MB.json):
COG-Query-AddFullText-less-1MB-less-32K-chars.bat query-match-path-no-fullText-less-1MB.json