Cognitive Suite Requirements
This guide covers the hardware and software requirements for Shinydocs Cognitive Suite, and includes the following components: Cognitive Toolkit, Analytics Engine, and Visualizer.
Your solution from Shinydocs may include other products such as Enterprise Search. Please see additional requirements needed for other Shinydocs products.
Overview
The requirements for the Analytics Engine depend on the volume of data to be analyzed. Depending on that volume you may require multiple machines. This guide will inform you of how many machines are required or recommended, and the specifications that need to be met for each machine.
The Analytics Engine, Coordinator nodes, and Cognitive Toolkit hardware requirements recommendations are based on years of experience crawling and analyzing data for organizations around the world.
The technology used by these products scales horizontally, meaning that if additional resources are required, they are additional, identically configured machines.
Power in Numbers
The Shinydocs Cognitive Toolkit, Analytics Engine, and Visualizer power most of the solutions offered by Shinydocs. These components are split out into 4 parts (5 if a Coordinator node is used):
Cognitive Toolkit | Backend (Worker) |
Shinydocs Extraction Service | Backend |
Analytics Engine | Backend |
Coordinator node | Backend |
Visualizer Interface | Frontend |
What is the Shinydocs Cognitive Toolkit?
The Cognitive Toolkit contains the tools needed to achieve the solutions provided by Shinydocs. You can think of these machines as workers. The workers reach out to your data to gather information (metadata, identifiers, text, etc) from the source, they can also perform work on the index (enrichment, finding duplicates, etc.). The more workers you have, the more they can accomplish by combining their efforts. You will need at least 1 worker to get started. As your need for performance becomes greater, you can add additional machines with the Cognitive Toolkit installed. They can also be removed should your needs change. Processes like text extraction and OCR are quite intensive for the CPU of these machines, the more resources you can give these machines, the faster it can process information.
What is the Shinydocs Extraction Service?
This service is installed with the Cognitive Toolkit. The Cognitive Toolkit now uses this service for extracting text from documents as well as providing the engine for extracting entities from your documents should you wish to.
What is the Analytics Engine?
The Analytics Engine (powered by Elasticsearch®) nodes are the core of the data solutions provided by Shinydocs, the brain. These machines house and serve all the data you collect from your systems in an index or indices. Using clustering technology, the nodes work together to distribute the load of all the information we gather about your data. These machines don’t store your files, your files can stay right where they are. The Analytics Engine machines store the metadata, text, and enrichments performed by the Cognitive Toolkit and provide a visual interface for exploring and visualizing your data. They scale very well and need to be scaled according to your volume of data. These machines need to be fast, like a brain is, to receive and serve data to the Cognitive Toolkit, Discovery Search, and the visual frontend. The faster the brain is, the faster everything connected to it can function.
What is a Coordinator Node?
When there is a large volume of data, a coordinator node assists the environment in a similar way a network load balancer would. These specialized nodes act as the centralized endpoint for the visual interface and the Cognitive Toolkit(s), simplifying configuration and ensuring the cluster of Analytics Engines are working efficiently.
What is the Visualizer?
The Visualizer is a web application interface that allows you to discover and visualize your data. Using a web browser (Google Chrome™ or Microsoft Edge® supported), operators will be able to access all crawled information, enrichments, and visualizations. Like other popular Business Intelligence and Analytics tools, the Shinydocs Visualizer Interface can help in creating beautiful graphs, charts, and tables. Operators will be able to search across your data set to discover what your data is telling you. Access to this tool can be controlled via a reverse proxy, however, it should be noted that the contents within the web UI are not individually permissioned based on user or group(s).
This web application would be installed on 1 of the Analytics nodes, or, if your data volume requires a Coordinator node, is installed on the Coordinator node.
Getting the most out of this guide
Ready to get started? Here is a step-by-step of the key information and where you'll find it in this guide so that you can successfully implement the Analytics Engine, Visualizer, and Cognitive Toolkit.
Check your organization's expected data volume
Match your expected data volume in the Table: Data Volume to Nodes provided
Using the table, you will now know how many Analytics nodes you will need
If your corresponding data volume suggests a Coordinator node, that is in addition to the Analytics nodes
Use the Analytics Engine & Coordinator Node Hardware Requirements table to see the hardware requirements and software prerequisites per node
Since storage requirements are split across the index cluster, for storage requirements, see Storage Sizing
Check the Shards section to match your per index data volume with the recommended shards
Determine how many Cognitive Toolkit machines you want to use. These are the workers, the more you have, the greater the throughput you will achieve. We have recommendations based on your data volume
Requirements for Cognitive Toolkit Machines can be found in the Cognitive Toolkit Machine Requirements section
Software prerequisites for Cognitive Toolkit can be found in the software prerequisites section
Review the Anti-Virus and Security, Repository-Specific Requirements, Access and Security, and Best Practices sections
Congratulations, you’re ready to install!
Analytics Engine & Coordinator Node Requirements
How many do I need?
The number of Analytics Engines you require is based on the volume of data that the tools will crawl and analyze.
Note: These recommendations are for production environments and may differ from small testing specifications.
Table: Data Volume to Nodes
Assumptions:
~1,000,000 files per terabyte of data volume
~70% of that data is text extractable
Data volume is per index. If data is being split into separate indices (e.g. an index per department) use that departments data volume for this calculation
Your Data Volume | |||||
1 – 40 TB | 50 – 100 TB | 200 – 400 TB | 500 - 700 TB | 800 TB – 1 PB | |
Number of Analytics Engines (nodes) | 1 | 3 | 4 | 6 | 9 |
Number of Coordinator nodes for production | 1 | 1 | |||
Total nodes | 1 | 3 | 4 | 7 | 10 |
Note: The use of 2 analytics nodes is not recommended.
You will need 3+ nodes to avoid index data loss in the event of a system failure
SharePoint Scans
There is a limit of 1000 SharePoint subsites per analytics node. If there are more than 1000 subsites in SharePoint, an additional analytics node is required, regardless of data volume.
Equation: [Number of SharePoint subsites]/1000 = Number of analytics nodes (rounded up)
For example: If ACME Corp has 2,500 subsites in SharePoint with 20 TB of data, 3 analytics nodes are required. (2500/1000 = 2.5=3 analytics nodes)
Why does this component need these resources?
The Analytics Engine is unlike most enterprise software. This technology needs to house all the metadata and text of your files, but also:
Stores the extracted text data of files
Computes very large workloads when visualizing data
Examples: Calculating the sum of millions and millions of file’s sizes, searching all ingested data for keywords, calculating counts of all extensions, tokenizing words, etc.
Serves data to the Cognitive Toolkit for processing
It needs to be fast, otherwise, it would take years to go through the volumes of data enterprises keep
These requirements and recommendations are designed to give you and your organization a performant solution that can meet your business needs.
Hardware Requirements
Dedicated machine(s) are required. The Analytics Engine & Coordinator nodes require dedicated hardware resources as outlined in the following sections
Table: Analytics Engine & Coordinator node Hardware Requirements
Component | Requirement for production environments (per node) |
CPU (cores) | 12+ |
Memory | 64 GB |
Storage | High-Performance NVMe SSD* (See Storage Sizing) |
Network | 10 Gbps interface |
Shinydocs cannot guarantee specific throughput or performance due to various environment variables.
If your organization’s hardware does not meet these requirements, you may experience slower performance and throughput with a higher error rate
CPU
Modern x86 64-bit enterprise-grade processor with 12 or more cores (Intel recommended)
More cores can be added to achieve higher performance
Due to the varying hardware and needs from organization to organization, you may need additional cores than noted above based on your desired performance
Dedicated cores preferred to vCores
Minimum 1.6 GHz per core
No VM execution cap
Memory
Maximum supported memory per node is 64 GB
If there is still insufficient memory in the cluster, additional nodes of the same hardware configuration should be added to the cluster
Enterprise-grade with Error-Correcting Code (ECC)
Dedicated memory is preferred
The Analytics Engine has a large memory footprint that is locked upon the service starting
Storage
Search speed and responsiveness is heavily dependent on the speed of your drive IO performance, latency, and throughput
Local storage required
Shared, network or remote-cloud storage is not supported due to performance
See Storage Sizing for details
SSD (NVMe preferred)
Random Read: >1000 MB/s @ 100% Utilization
Sequential Read: >2000MB/s @ 100% Utilization
Sequential Write: >2000MB/s @ 100% Utilization
Latency Maximum: <3.00ms
Note: Above must be supported on the backplane of allocated servers.
Dedicated disk performance per machine must be at or above recommendation.
Disk performance must be maintained if other VMs use the same disk(s).
Network
Local switch
Server grade hardware with:
No routing/load balancing between devices
10 Gigabit Network Interface on all nodes
10 Gigabit Line between nodes
Software Prerequisites
Windows Server® 2019 or newer
📚 See https://learn.microsoft.com/en-us/windows-server/get-started/windows-server-release-info for more information on end-of-support dates for Windows Server
Java®/OpenJDK/Amazon Coretto® 11
Shinydocs Indexer and Visualizer package
We will share a special link just for you and your organization to download this package
Storage Sizing
When sizing storage for Analytics Engine nodes, you need to decide if text extraction is in your use-case. Text extraction greatly increases the storage requirement, as the index needs to store that text. Storage sizing correlates to the number of files in your data volume. Since it is difficult for most organizations to determine this before using the Cognitive Suite, storage sizing is determined by the volume of data. Due to the unpredictable nature of enterprise data, once your data has been crawled and text extracted, there may be an opportunity to shrink the unused storage. You may also need to expand your storage if required. It is easier and more efficient to start large and scale back as needed.
Note: With a cluster of Analytics Engines, the storage requirement is divided across the nodes.
[Storage Requirement] ÷ [Number of nodes] = Free disk space required per node.
Once a node reaches 90% capacity, the node’s index data will become read-only to prevent filling the drive completely. Any storage that has reached 85% capacity should be considered “low” and additional space allocated to it to avoid putting the cluster into read-only.
Coordinator nodes
30 GB minimum on non-OS drive
Analytics Engine nodes
Without extracted text Metadata (Inc. ROT, hash values, additional metadata) | With extracted text Metadata (Inc. ROT, hash values, additional metadata) |
1% of your data volume on non-OS drive | 10% of your data volume on non-OS drive |
Table: Data Volume to Required Storage Examples
Expected Data Volume | No extracted text | With extracted text |
1 TB Approximately 1,000,000 files | 10 GB Free space (combined) Distributed across 1 Analytics Engine node Node 1: 10 GB | 100 GB Free space (combined) Distributed across 1 Analytics Engine node Node 2:100 GB |
100 TB Approximately 100,000,000 files | 1 TB Free space (combined) Distributed across 3 Analytics Engine nodes Node 1: 341.3 GB Node 2: 341.3 GB Node 3: 341.3 GB | 10 TB Free space (combined) Distributed across 3 Analytics Engine nodes Node 1: 3.33 TB Node 2: 3.33 TB Node 3: 3.33 TB |
1 PB Approximately 1,000,000,000 files | 10 TB Free space (combined) Distributed across 9 Analytics Engine nodes Node 1: 1.11 TB Node 2: 1.11 TB Node 3: 1.11 TB Node 4: 1.11 TB Node 5: 1.11 TB Node 6: 1.11 TB Node 7: 1.11 TB Node 8: 1.11 TB Node 9: 1.11 TB | 100 TB Free space (combined) Distributed across 9 Analytics Engine nodes Node 1: 11.11 TB Node 2: 11.11 TB Node 3: 11.11 TB Node 4: 11.11 TB Node 5: 11.11 TB Node 6: 11.11 TB Node 7: 11.11 TB Node 8: 11.11 TB Node 9: 11.11 TB |
Shards
Shards are pieces or fragments of data stored by the index on an index by index basis (i.e. primary shards). These shards are also replicated (i.e. replica shards) for clusters that have 3 or more nodes. When crawling your data with the Cognitive Toolkit, by default, it will create your index with 5 primary shards and 1 replica per primary. When combined it equates to 10 shards.
Primary Shards | Replica Shards (# of replica shards for each primary shard) | Shard Layout | Total Shards |
1 | 1 | P1 R1 | 2 |
5 | 1 | P1, P2, P3, P4, P5 R1, R2, R3, R4, R5 | 10 |
10 | 1 | P1, P2, P3, P4, P5, P6, P7, P8, P9, P10 R1, R2, R3, R4, R5, R6, R7, R8, R9, R10 | 20 |
Table: Data Volume to Shards
Assumptions:
~1,000,000 files per terabyte of data volume
~70% of that data is text extractable
Data volume is per index. If data is being split into separate indices (e.g. an index per department) use that department data volume for this calculation
Index Data Volume | Without Text | With Text | ||
Primary Shards | Replica Shards | Primary Shards | Replica Shards | |
Up to 100 TB | 5 | 1 | 5 | 1 |
200 TB | 5 | 1 | 10 | 1 |
300 TB | 5 | 1 | 15 | 1 |
400 TB | 5 | 1 | 20 | 1 |
500 TB | 5 | 1 | 25 | 1 |
600 TB | 6 | 1 | 30 | 1 |
700 TB | 7 | 1 | 35 | 1 |
800 TB | 8 | 1 | 40 | 1 |
900 TB | 9 | 1 | 45 | 1 |
1 PB | 10 | 1 | 50 | 1 |
1,000 shard limit per cluster
Cognitive Toolkit Machine Requirements
Since the Cognitive Toolkit is the worker for your data, machines running it should be placed as close to the data as possible. For processes like hashing and text extraction, the toolkit needs to load that file to extract the contents. The closer the toolkit is to the data, the quicker it can load the files to extract them. This is more performant than having to load files over a great physical distance.
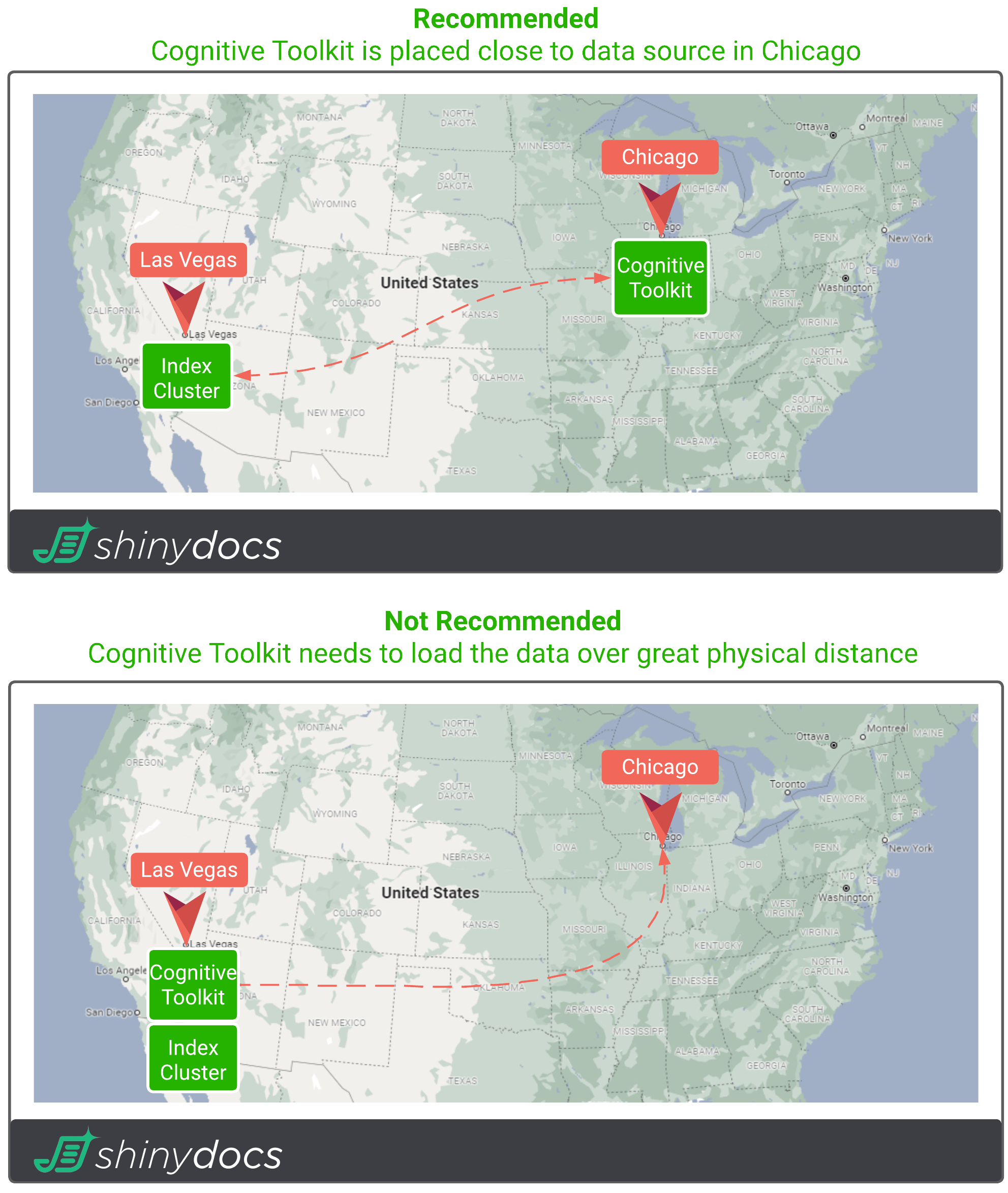
Hardware Prerequisites
The Shinydocs Cognitive Toolkit is your data worker, these machines are separate from the Analytics Engines and have different requirements. In most cases, more Cognitive Toolkit machines will improve throughput. The Cognitive Toolkit requires dedicated hardware resources as outlined in the following sections.
Table: Cognitive Toolkit Machine Hardware Requirements
Component | Recommendation for production environments (per machine) |
CPU (cores) | 8+ |
Memory | 32 GB+ |
Storage | 20 GB – SSD (non-OS) or similarly performing drive array |
Network | 1+ Gbps interface |
Shinydocs cannot guarantee specific throughput or performance due to various environment variables.
If your organization’s hardware does not meet these requirements, you may experience slower performance and throughput with a higher error rate
CPU
Modern x86 64-bit enterprise-grade processor with 8 or more cores (Intel recommended)
More cores can be added to achieve higher throughput in text extraction, hashing, and OCR
Due to the varying hardware and needs from organization to organization, you may need additional cores than noted above based on your desired performance
Dedicated cores preferred to vCores
Minimum 2.0 GHz per core
No VM execution cap
Memory
Additional memory may be required to achieve your desired performance
Dedicated memory is preferred
The Analytics Engine has a large memory footprint that is locked upon the service starting
Storage
Local storage required
Shared or network storage is not supported due to performance
SSD preferred, but not required
Network
Server-grade hardware with:
1 Gigabit per second Network Interface preferred
Software Prerequisites
Windows Server® 2012 r2 or newer (Server 2016 & 2019)
Java®/OpenJDK/Amazon Corretto® 11 (For Shinydocs Extraction Service)
When using IronOCR for .NET, Visual C++ Runtime (64 bit) for Windows is required. 📚 See the Microsoft article: https://docs.microsoft.com/en-US/cpp/windows/latest-supported-vc-redist?view=msvc-170#visual-studio-2015-2017-2019-and-2022 (64-bit only)
Recommended Cognitive Toolkit Machines
It is up to you and your organization on how many Cognitive Toolkit machines you want to deploy. One of the great features of Shinydocs Cognitive Suite is how simple it is to scale up, you can start with 1 and go to 25 depending on your needs. For example, with Shinydocs Discovery Search, having up-to-date index data is important for the search experience. You can add and remove Cognitive Toolkit machines to meet your timing needs. These are our recommendations based on lab and customer testing.
Note: Some sources may not benefit from additional Cognitive Toolkit machines. These sources (like SharePoint Online) have throttle limits, additional Cognitive Toolkit machines cannot bypass those throttle limits.
Table: Recommended Cognitive Toolkit Machines Based on Data Volume
Assumptions:
~1,000,000 files per terabyte of data volume
~70% of that data is text extractable
Data volume is per index. If data is being split into separate indices (e.g. an index per department) use that departments data volume for this calculation
Your Data Volume | |||||
1 – 40 TB | 50 – 100 TB | 200 – 400 TB | 500 - 700 TB | 800 TB – 1 PB | |
With Text Extraction Recommended Cognitive Toolkit Machine(s) | 1 | 2 | 4 - 8 | 10 - 14 | 16 - 20 |
Without Text ExtractionRecommended Cognitive Toolkit Machine(s) | 1 | 1 | 2 - 4 | 5 - 7 | 8 - 10 |
With Text Extraction: Approximately 1 Cognitive Toolkit Machine per 50 TB of data volume
Without Text Extraction: Approximately 1 Cognitive Toolkit Machine per 100 TB of data volume
Why does this component need these resources?
The Shinydocs Cognitive Toolkit and Extraction Service, as mentioned, are the workers for your data. Hashing, text extraction, OCR, entity extraction, and more are very compute-intensive processes. They require high-performance hardware not only to be able to process your data but do it as quickly as it can. You can easily benchmark the performance of different CPU configurations in your environment if you want. These requirements and recommendations are designed to give you and your organization a performant solution that can meet your business needs.
Example Configurations
Here are some examples to aid in the understanding of how these components work together. As noted, the number of Cognitive Toolkit machines is flexible based on how fast you want to process data. These examples use the recommendations in this guide.
1 TB Data Volume
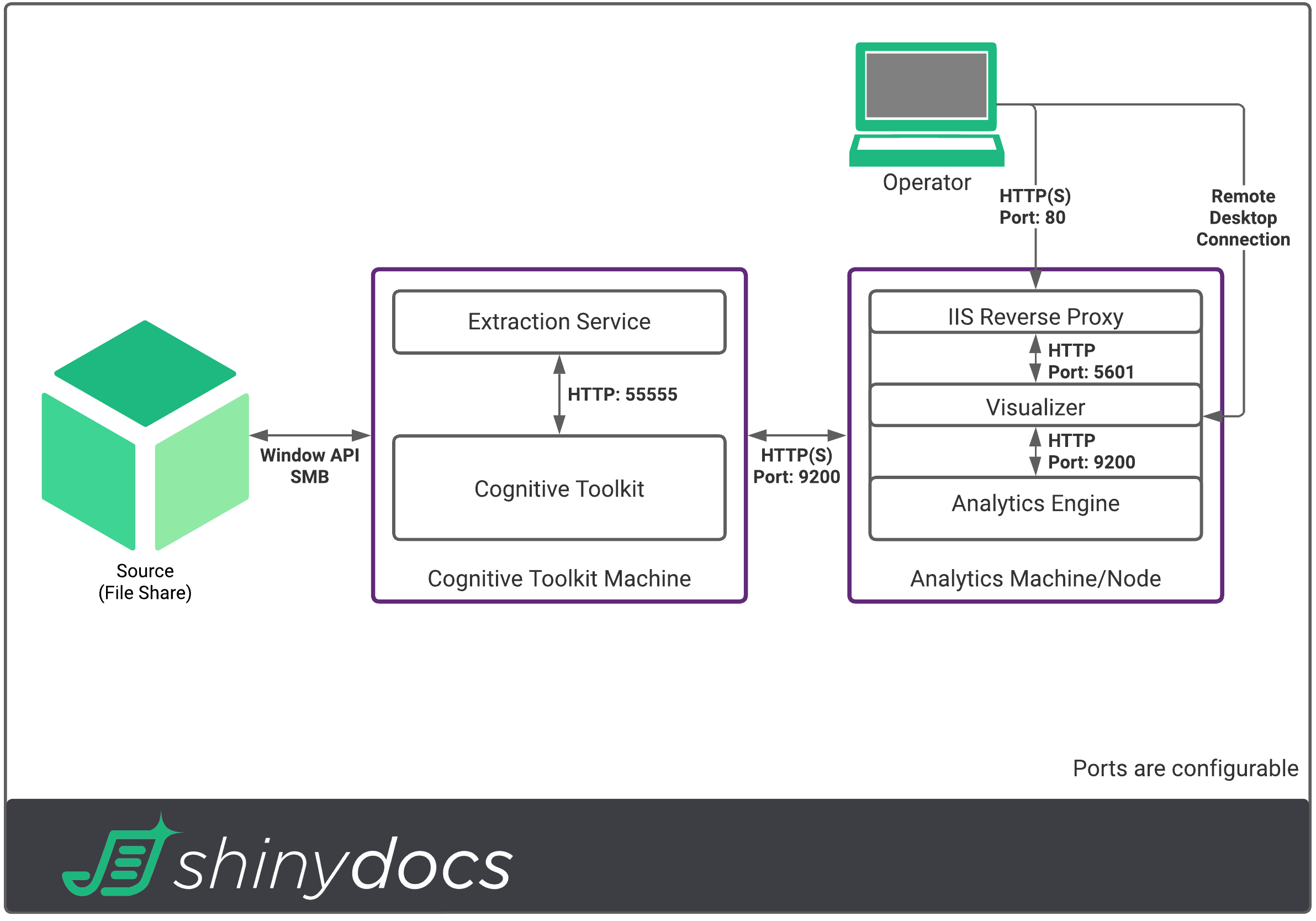
100 TB Data Volume
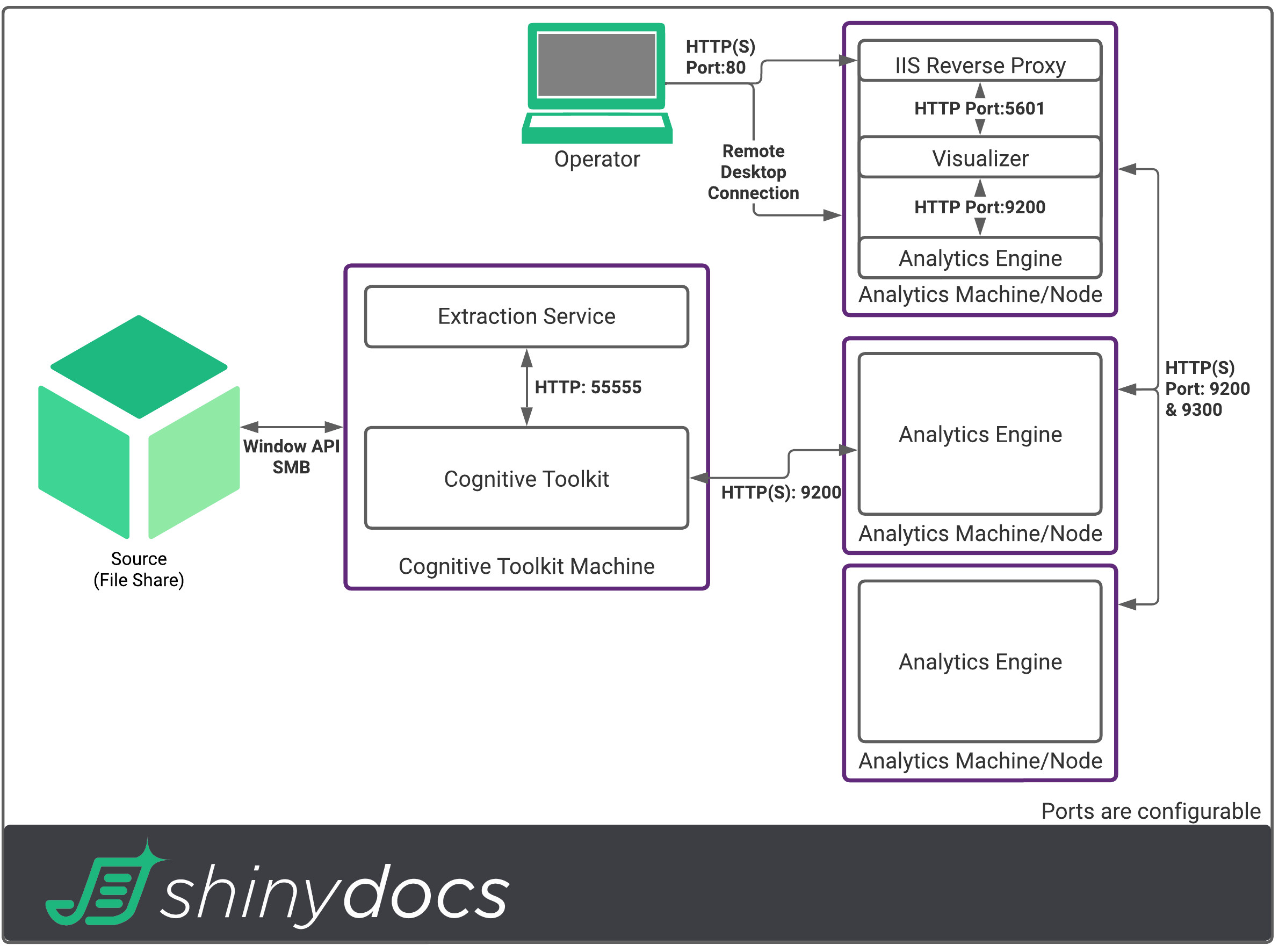
500 TB Data Volume
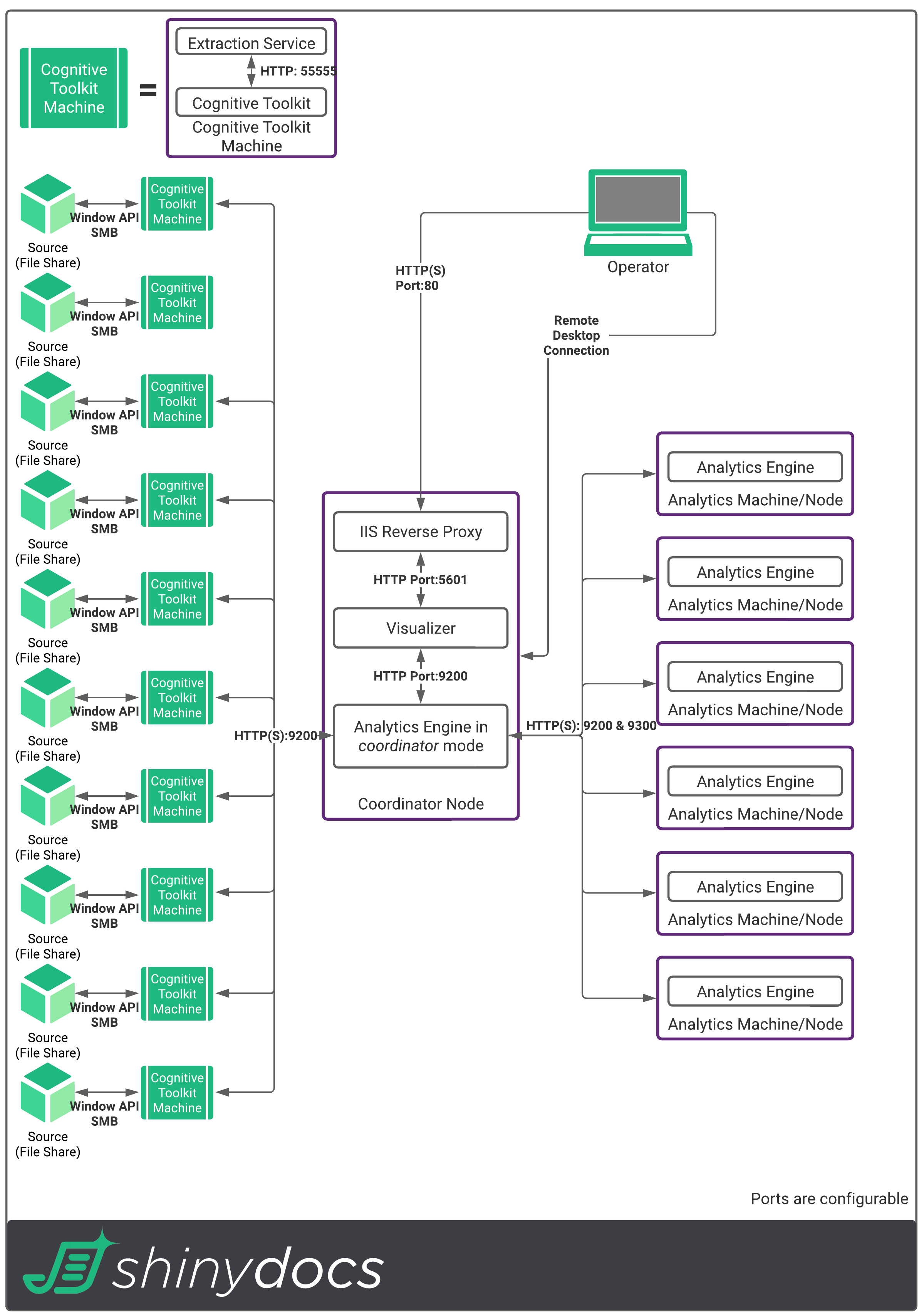
Antivirus and Security
For the performance and stability of Shinydocs Cognitive Suite, ensure you have set up the proper exclusions with your security/Antivirus solutions. While these items should be scanned before they are installed, we do not recommend operation without exclusions. These exclusions are for the server(s) running the Cognitive Suite solution (Analytics Engine nodes, Cognitive Toolkit Machines).
Note: The Cognitive Toolkit and the indices it ingests data into do not store your files, only the metadata. The index should be free from AV scans (on-demand, real time, scheduled) when in operation.
Anti-Virus Directory Exclusion List
Note: For simplicity, it may be easier for your security team to exclude one path. Add an exclusion for [drive]:\shinydocs AND place all products in that directory. Your environment may differ slightly. The following list is assuming you have installed the solution on the D:\ drive. Please adjust based on your actual installation
D:\Shinydocs\indexer
D:\Shinydocs\visualizer
D:\Shinydocs\cognitive-toolkit-x.x.x.x
Note: This is the directory that would contain the Cognitive Toolkit executable and dependencies for the executable
Other Considerations
There will be a significant negative performance impact on crawling, extracting hash values, and text extraction for files on a source (ex. File share, Content Server) if the source is actively scanned by Anti-Virus solutions. Crawl speeds will be limited by the throughput of the Anti-Virus processes.
Disable any scanning of local network traffic on the servers the Cognitive Toolkit solution is installed on
Disable the scanning of network traffic between server nodes for the Analytics Engines. This traffic operates on ports 9200 and 9300 unless configured otherwise
Repository-Specific Requirements
Since the Cognitive Toolkit connects to many popular repositories, it is important to review these requirements to minimize access-related/firewall issues that can surface.
Microsoft SharePoint® (Online Office 365)
Authentication to Microsoft SharePoint® Online (Office 365) requires Azure application registration
It is required that the servers running the Cognitive Toolkit can access the site root and all sub-sites.
An easy way to check if this connection can be made is via web browser, though more advanced methods do exist (example:
https://ACMECorp.sharepoint.com/site)Either an internet connection is required or a network proxy must be set to allow the Cognitive Toolkit machine to connect to:
https://<site_name>.sharepoint.comhttps://accounts.accesscontrol.windows.net
Azure app registration permissions for Sharepoint® Online (Office 365)
Crawl | Migration (destination) |
Sites.Read.AllProvides read access to Sharepoint® site collections | Sites.ReadWrite.AllAllows the crawling account write access to sites/libraries |
Microsoft SharePoint® (On-Premise)
Authentication to Microsoft SharePoint® on-premise requires an administrator username and password
It is required that the servers running the Cognitive Toolkit can access the site root and all sub-sites.
An easy way to check if this connection can be made is via web browser, though more advanced methods do exist (example:
https://ACMECorp.sharepoint.com/site)
Service account permissions for Sharepoint® (on-premise)
Crawl | Migration (if destination) |
Full Read - Has full read-only accessProvides read access to Sharepoint site collections | Full Control - Has full controlAllows the crawling account write access to sites/libraries |
Microsoft Exchange® Online (Office 365)
We offer two methods of authentication to Microsoft Exchange® Online
Username and password
Azure® app registration
It is required that the servers running the Cognitive Toolkit can access EWS (Exchange Web Services)
An easy way to check if this connection can be made is via web browser, though more advanced methods do exist (example:
https://outlook.office365.com/ews/exchange.asmx)For Microsoft Exchange Online®, either an internet connection is required or a network proxy must be set to allow the Cognitive Toolkit machine to connect to:
https://outlook.office365.comhttps://login.microsoftonline.com
Service Account Permissions
Azure® Office 365 Exchange Online API | Username and Password Authentication |
full_access_as_app Provides full access to mailboxes for the purpose of crawling | ApplicationImpersonation Allows the crawling account to impersonate each of the users and mailboxes |
Grant Admin Consent Required step in Azure App Registration | |
Mailbox Search permission required for the email account used to crawl | |
Microsoft Exchange® (On-Premise)
Authentication to Microsoft Exchange® on-premise requires a domain username and password
It is required that the servers running the Cognitive Toolkit can access the Exchange WSDL site.
An easy way to check if this connection can be made is via web browser, though more advanced methods do exist (example:
https://ACMECorp/ews/Exhange.asmx)
Administrator service account permissions:
ApplicationImpersonation role
Mailbox Search role
OpenText™ Content Server
We offer two methods for crawling operations in Content Server:
Database & REST (best option, most performant)
REST only (slower, no database connection required)
If you are using the Database and REST method:
Database connection information (example:
10.0.255.254:1521)Database Name (SQL) or Schema (Oracle)
Username and password for the database
Database account with Read Access to:
DTREE
KAUF
DVERSDATA
LLATTRDATA
CATREGIONMAP
Content Server account to authenticate at REST with read permission (and write if migrating to Content Server)
Access to Content Servers database from server running Cognitive Toolkit (example:
10.0.255.254:1521)Access to Content Server URL (ex.
http://acmecorp.com/otcs/cs.exe) from server running Cognitive Toolkit
If you are using the REST only method:
Content Server account to authenticate at REST with read permission
Access to Content Server URL (ex.
http://acmecorp.com/otcs/cs.exe)
If you are migrating to OpenText™ Content Server, our Shiny Service module for Content Server is required
Note: Complex redirects when accessing Content Servers endpoint or using self-signed certificates could result in the Cognitive Toolkit being unable to connect. Ensure your environment supports access to this site from the machine the Cognitive Toolkit is installed on, and has the appropriate certificates installed as a trusted root
OpenText™ Documentum™
Access to Documentum endpoint URL from server running Cognitive Toolkit
Example:
http://localhost:8080/documentum-rest-endpointAccount with read permission (and write if migrating to Documentum)
IBM® FileNet®
Access to FileNet URL
Example:
http://ACMECorp.com:9443/wsi/TISKVJE87WCWEAccount with read permission (and write if migrating to FileNet)
Box Inc.
Access to Box URL from server running Cognitive Toolkit
Example:
http://box.com
Box application service account
Box dev console
For Box, either an internet connection is required or a network proxy must be set to allow the Cognitive Toolkit machine to connect.
Note: Box™ by Box Inc. has API limits that can incur costs to your organization. While the Cognitive Toolkit uses these API calls efficiently, depending on the volume of your data, you may go over your API limit. Please consult with your Box representative for more information.
Access and Security
Accessing and Crawling Your Data Sources
Service Accounts
When getting ready to crawl or migrate your data, it is necessary to provide access to the data so it can be crawled and if migrating, can be ingested into the destination repository. Here are some guidelines for creating service accounts when working with Shinydocs Cognitive Suite. Shinydocs offers tools to encrypt and store your passwords used to connect to non-Windows repositories (Content Server, SharePoint, etc.). 📚 See Encrypting repository passwords with SaveValue.
Crawling Data – Metadata, Hash Values, Text Extraction
The phrase “Crawling Data” is an umbrella term that essentially means reading your data. Crawling is a read-only process that pulls data from your source repository. When preparing to crawl a source repository, it is a good practice to set up a service account for access to the source. This service account would also be used to run the Cognitive Toolkit, the toolkit needs the access of this service account to ensure it can gather all the information about your data, the service account will need the ability to:
Read all files in the source
Ensure the service account has access to all sub-items, as some repositories support disabled inheritance of permissions
Is allowed to run applications (exe), batch files, and PowerShell files on the machine the Cognitive Toolkit is installed on
Is allowed to be used in interactive sessions
Can be logged in without manual authentication (to run scheduled tasks)
Actioning Data – Disposal
Depending on your organization's use-case of Shinydocs Cognitive Suite there may come a time where you want to dispose of ROT. In order to dispose of data on your source, you will need to ensure:
All requirements from Crawling Data – Metadata, Hash Values, Text Extraction have been met
The service account has delete permissions (sometimes this role is rolled up into write permissions)
Actioning Data – Migration
If you are using the Shinydocs Cognitive Suite to migrate files into an ECM, you will need to ensure:
There is a service account (via Active Directory or built-in user manager) on the ECM the Cognitive Toolkit can use and that the operator has those credentials
The service account will need read and write permissions in the destination repository
Some ECM solutions and their custom modules may have additional permissions needed (example: permission to assign classification values)
Check that any area the Cognitive Toolkit will write to has permissions to do so (example: categories in Content Server)
Component Specific Security
The Visualizer and Analytics Engine are the key components that your organization will need to control access to. This section will let you know which components should be secured by your organization and some of the options you have for securing them.
Visualizer
The Visualizer front end can be locked down by forcing the Visualizer to only talk locally (binding to 127.0.0.1). From there, an IIS reverse proxy (or a commercially available reverse proxy solution of your choice) can be created to not only encrypt the connection with your organization's SSL certificate but also leverage your Active Directory to gain access to the web application.
Note: Anyone who has access to the Visualizer, will have access to all contents and data in the Visualizer. There are no role-based permissions within the Visualizer. See Best Practice: Securing Shinydocs Visualizer access (Reverse Proxy in IIS) for more information regarding the setup of the reverse proxy in IIS.
Analytics Engine
The Analytics Engine is a backend service that contains a REST API. This REST API is accessible on the network (default port 9200). It is critical that your organization secures these connections to prevent malicious users from accessing data they should not. Follow your organization's standards for securing REST APIs and ensure the correct firewall rules are made.
The Cognitive Toolkit machines must be able to communicate with the Analytics Engines via HTTP/HTTPS (or the Coordinator node if your implementation requires it).
Each of the Analytics Engines needs to be able to communicate with each other via HTTP/HTTPS
SSL
The Visualizer and Indexer can be configured to communicate via SSL.
📚 See Configuring SSL for Shinydocs Indexer.
Best Practices
We have been crawling data for years, in that time, we have learned a lot about some of the situations your organization can face with the technical implementation of the Cognitive Suite. Below are some of the best practices we have found to help make your implementation successful.
Installation
The Shinydocs Cognitive Toolkit should be installed on its own dedicated machine. The Cognitive Toolkit and the Analytics Engines are very powerful tools and require powerful hardware, problems can arise when both applications need a lot of resources. Having these components on separate machines prevents them from competing for CPU, memory, and storage IO.
It is best for large volumes of data to use the Shinydocs Jobs index to track metrics from the Cognitive Toolkit. This index includes information about crawls that have been completed and details about their operation. 📚 Check out Setting up the shinydocs-jobs index for more information on configuration and some of our pre-built visualizations and dashboard.
If your implementation suggests a Coordinator node, the Visualizer is best suited to be installed on that machine. This gives the Visualizer a direct connection to the cluster so it can retrieve data from the index without making a network hop. If your implementation does not suggest a Coordinator node, the Visualizer can be installed on any of the Analytics Engine nodes.
When naming your Analytics Engine nodes in the elasticsearch.yml configuration, choose a unique name that will help identify that node from the others. A common method is to name the node after the server’s machine name. That way if there are any problems, the machine with the problem can be identified easier
Ensure your organization has a way to secure access to Analytics Engine nodes. Some organizations segment their Analytics Engine cluster on the network, poking secure holes in the environment as needed. Others simply use their existing firewall solution.
Operation
Anti-Virus and packet inspection products can severely slow down the performance of the Cognitive Suite. This includes on-access type scanning used by some organizations in their source repositories (i.e., file share). Meaning that every time the toolkit seeks information from a file, that file will be scanned before the toolkit can get that file’s data. Depending on your AV, you could see a 0.5x to 50x reduction in performance due to these processes.
Do not run multiple processes that could collide with each other (e.g., running a tagging script while a crawl operation is happening). An entry in the index can only be updated by one process at a time, failure to do so can result in 409 errors aka “version conflicts”. These conflicts can stop processes from completing fully. Be sure to factor this into your scheduled tasks and have the separate processes run in serial (e.g., all of the metadata crawling happens before hashing). 📚 See Cognitive Suite Crawling and Race Conditions.
For scheduled tasks, it is better to have separate Cognitive Toolkit directories for each repository (sometimes more than one for large data volumes). This allows for easier troubleshooting should something go wrong and the logs need to be inspected. You will know which log files, queries, script files etc. are relevant to that repository.
It is recommended to have Windows Error Reporting (WER) enabled on all servers using components of Shinydocs Cognitive Suite. These errors can be helpful in troubleshooting issues that may arise in your environment. 📚 For more information, please see the Microsoft article: Enable-WindowsErrorReporting.
When using the Visualizer (Kibana), be mindful of what you are asking for when making visualizations on your data. Large and complex visualizations can be extremely demanding on the system and may take a long time to load, sometimes even timing out. If this happens, check that the scope of your visualizations is accurate and to the point. Filter out as much data as possible that is not relevant to your interests and/or adjust the size property of the individual visualizations.
While there is virtually no regular maintenance required for the index, there are some maintenance-related notes in our Customer Portal. 📚 See Maintaining your indices.
For Content Server crawls, please take into account background processes such as Agents, WebReports, maintenance, or other scheduled tasks related to your CS instance.
Requirements and Recommendations Matrix
Data Volume | Analytics Engines required | Coordinator Nodes required | Cognitive Toolkit machines recommended | Shards | ||
With Text | No Text | With Text (primary:replica) | No Text (primary:replica) | |||
1 TB | 1 | NA | 1 | 1 | 5:1 | 5:1 |
2 TB | 1 | NA | 1 | 1 | 5:1 | 5:1 |
5 TB | 1 | NA | 1 | 1 | 5:1 | 5:1 |
10 TB | 1 | NA | 1 | 1 | 5:1 | 5:1 |
20 TB | 1 | NA | 1 | 1 | 5:1 | 5:1 |
30 TB | 1 | NA | 1 | 1 | 5:1 | 5:1 |
40 TB | 1 | NA | 1 | 1 | 5:1 | 5:1 |
50 TB | 3 | NA | 2 | 1 | 5:1 | 5:1 |
100 TB | 3 | NA | 2 | 1 | 5:1 | 5:1 |
200 TB | 4 | NA | 4 | 2 | 10:1 | 5:1 |
300 TB | 4 | NA | 6 | 3 | 15:1 | 5:1 |
400 TB | 4 | NA | 8 | 4 | 20:1 | 5:1 |
500 TB | 6 | 1 | 10 | 5 | 25:1 | 5:1 |
600 TB | 6 | 1 | 12 | 6 | 30:1 | 6:1 |
700 TB | 6 | 1 | 14 | 7 | 35:1 | 7:1 |
800 TB | 9 | 1 | 16 | 8 | 40:1 | 8:1 |
900 TB | 9 | 1 | 18 | 9 | 45:1 | 9:1 |
1 PB | 9 | 1 | 20 | 10 | 50:1 | 10:1 |
Analytics Engine Node | Cognitive Toolkit Machine | ||
Component | Requirement | Component | Requirement |
CPU (cores) | 12+ | CPU (cores) | 8+ |
Memory | 64 GB | Memory | 32+ GB |
Storage | High-Performance NVMe SSD* (See Storage Sizing) | Storage | 20 GB SSD (non-os) or similarly performing drive array |
Network | 10 Gbps interface | Network | 1+ Gbps interface |
Once the requirements above are installed and ready, it’s time to install the Cognitive Toolkit! 📚 Refer to the instructions in Installing and Upgrading Cognitive Suite.